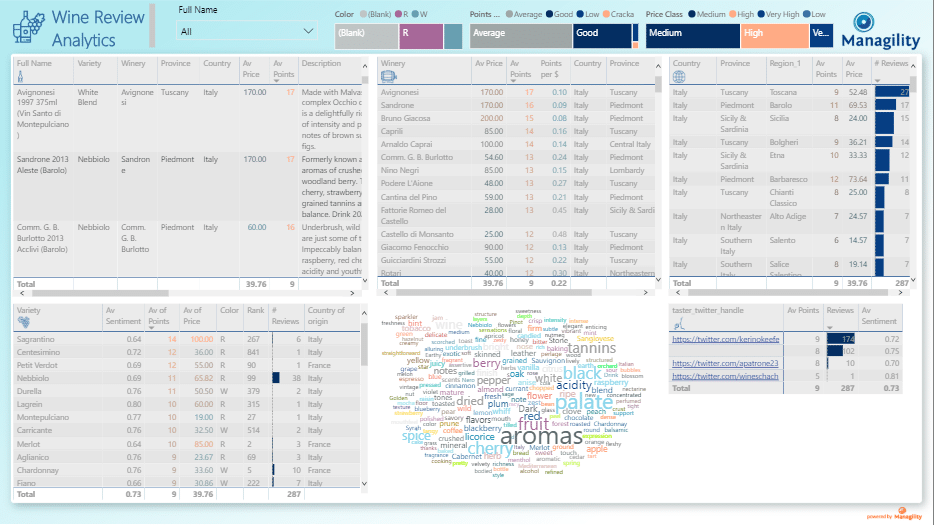
I love discovering and exploring wines (within healthy limits) and recently came across a Kaggle data set with 150k wine reviews by professional wine tasters covering wines around the globe. A dream come true…
The perfect start to test new powerful analysis features in Power BI and Data Flows, optimize information design and add additional details using API’s (like image links from search engines, etc.).
Here are the outcomes and what I learnt:
Data Preparation
Merging complementary data sets
Initially, I focused on what additional information could add insight value one thing for example that the data set didn’t include was the wine type (red, white, rose). I found a data set which contained wine attributes by variety which I joined with fuzzy merge. This worked reasonably well but around 30% couldn’t be matched.
This is In line with a lot of other projects in advanced analytics. It would take extensive efforts to address the outstanding 20-30% which I didn’t want to go to for this exercise.
Additional details
To assist with analysis, I added clusters for pricing and review points (when I started this project the new Key Influencer visual was only supporting categories. Now continuous variables are supported).
Then I came up with the idea that it would be a nice gimmick (admittedly not too much additional insight value) if users could see the wine label. For this I thought I could use the first picture link result when searching for wine name + “ label”. Initially I tried to use the Bing API using an invoked function in Power BI.
This worked but is unfortunately very slow and costly. Microsoft (with Google it’s similar) provides 3000 free calls to the Bing API from that point onwards it costs between $5-10 per 1000 transaction.
So, for 150k records a $750 investment. Not exactly cheap… What’s also a bot annoying with that is, that the preview in Power Query consumes 1000 calls and when you then subsequently apply the results for the report the function is triggered again for the 1000 that were already calculated. With the free 3 transactions per second limit it also takes a lot of time.
As a workaround one my colleagues -a Python expert- developed a script for me that automatically scrapes the image link from Bing searches and writes it into the data table. An approach that still takes a fair bit of time but without any charges (potentially not compliant with Bing TOS, though, be warned).
Advanced Analytics
Finally, I looked into getting interesting insights from “AI methods” (which I would call “advanced analytics”): With the text-based reviews key phrases and sentiment are typical candidates available in Azure Cognitive Services.
Initially, I tried the same approach as with the pictures using invoked API calls and faced the same issues as with search API: cost and speed. In a next step, I tried the new AI features in Data Flows. These require Power BI Premium Capacity which -based on the full monthly cost- is often considered out of reach for the average user but there is a way around this: Using the free Azure MSDN entitlement, you can setup an A2 embedded capacity that cost 50% less than full Premium. AND…
It’s is only charged based on actual use. For my purposes I setup the data flow on the CSV file and configured sentiment and key phrases for the text description. The initial load and calculation of the cognitive functions takes 30 minutes but then you only have to load it once into Power BI and can turn the capacity off as you won’t need it anymore as long as there is no refresh with the data set necessary. In the end running this for 150 thousand records resulted in charges on my entitlement of less than $100.
What I found here though, were strange results with the sentiment scores. Reviews that a clearly very positive had a very low score. I then ran this against the normal Azure Cognitive API and discovered that the results were way better and also very different in general to Data Flows ones. I brought this up with Data Flows program management but so far haven’t heard back.
Front End Tricks
In addition to applying the normal information design principles I developed a few new methods:

-
Using tree maps as filters
I really love the new filter pane but it has a problem with filters on the report: when you choose a filter in the page the drop down filter still shows “All” (when you open it you see the filtered result(s)). This is a problem not just from a usability but also when doing PDF exports as the consumers will not see the filter applied. My workaround was to use Treemaps with a Top N filter. This has the advantage that single filter times are shown nicely, and you can quickly change to another of the TOP N items.
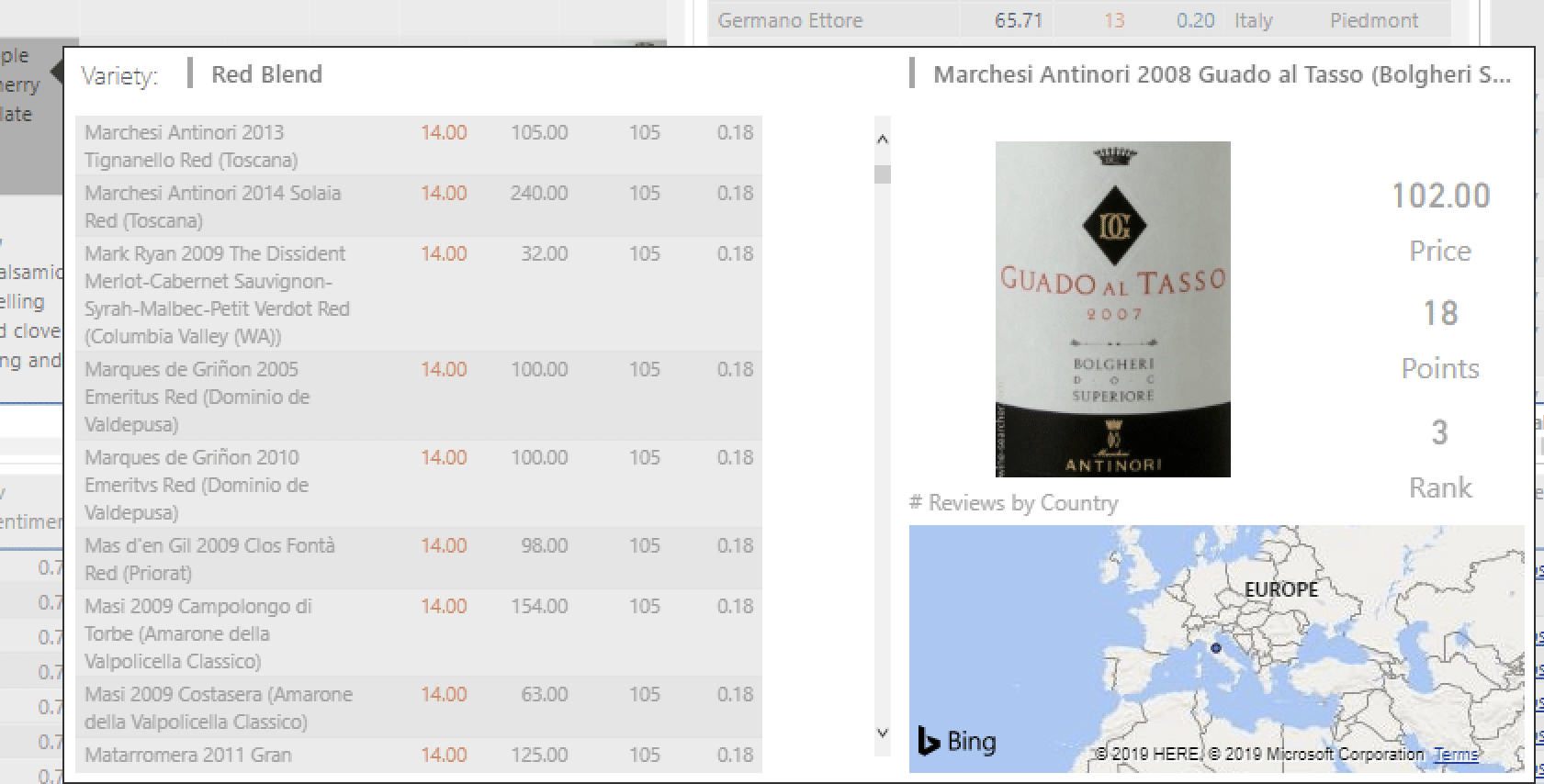
-
Custom Tooltips to Display Picture
Using the link from the search API I created a custom tool tip page with an image viewer visual that displays the label of the wine. One of those not too “insight driving” but “wow” features.
-
Correlation Visuals
Correlation is an important data science method I experimented with clustering in the inbuilt scatter plot, but it seems to have a bug with two calculated measures (average price/review points). For large amounts of data points, I would like to see an option to draw rectangles and filter arbitrary clusters, similar to what’s available in the ESRI map visual as well as statistical measures like correlation coefficient and Error. As an alternative that supports some of these, I found the “Correlation Plot” visual useful to visualize correlation coefficient for multiple measures in a matrix.
-
Key Influencer
By now already likely widely known: A game changer that also in this project provides tremendous insights. Now with continuing variables supported, the only thing that I am missing is outbound filtering in Key Influencer result set and custom tooltips to be able to further analyse interesting result sets.
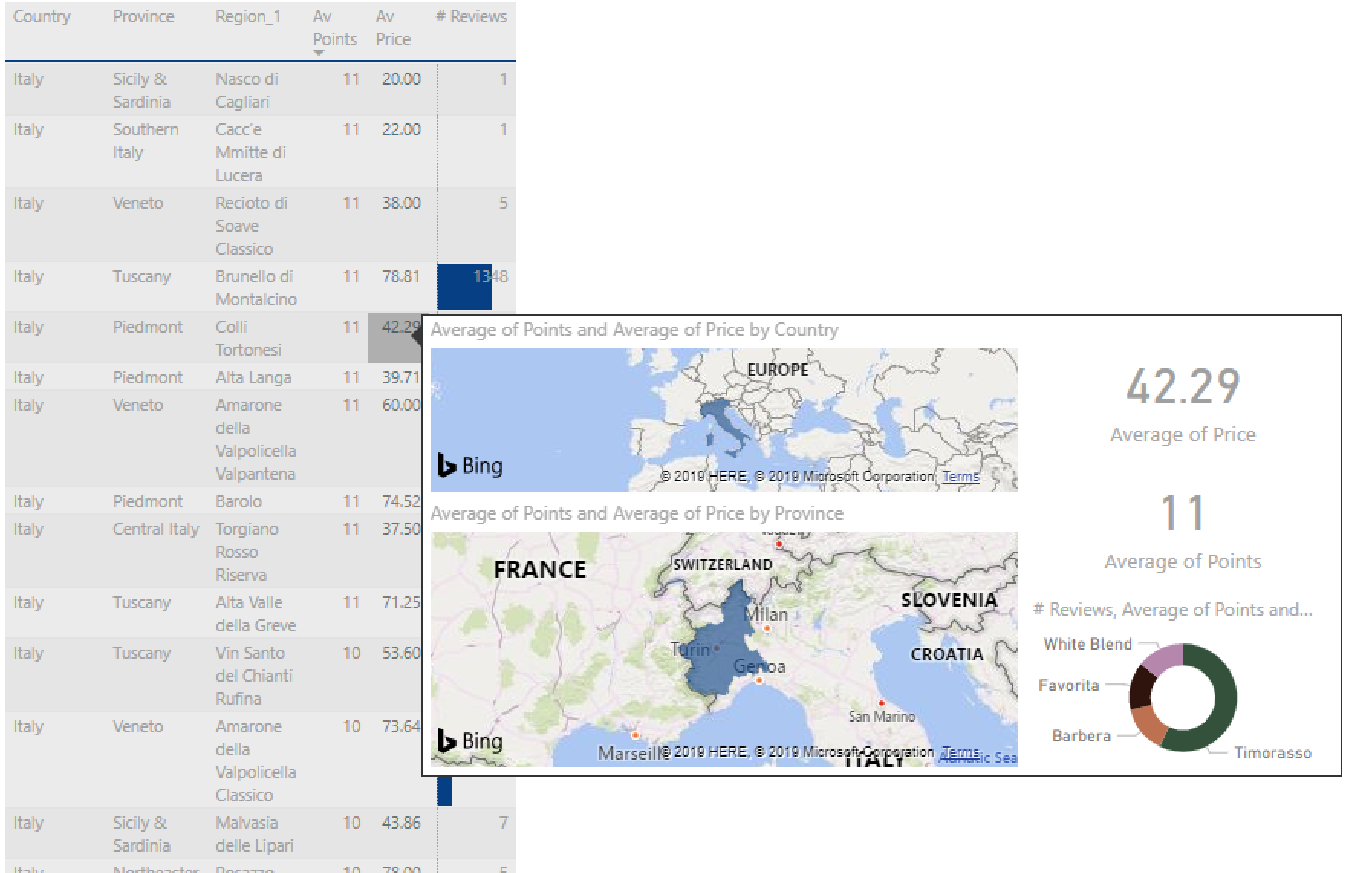
-
Use of visuals / preference for tables
In general -but particular in projects like this one, where you are dealing with a lot of analysis items- I am a big fan of table/matrix visuals. They might be not as “nice” and glossy as bars, lines, scatter or worst pie charts but they provide unparalleled analysis value particular in combination with custom tool tips.
Using many measures and attributes with large number of items in the rows is no problem in a table but likely impossible or useless in chart. Spice up your table with smart conditional formatting (by color or data bars / spark lines that in the end offer the same at a glance understanding of patterns in your data as most charts) as well as custom tool tips and you will likely never touch that pie chart again. This applies to any initial visualization that is not a simple dashboard where only a few measures are monitored.
The full wine reviews report will be part of our upcoming video training series so we can’t share the pbix publicly, but you can try a publish to web app with a limited data set (2000 records) below (unfortunately the filter pane, special visuals like Key Influencers and some other functionalities are not supported in publish to web so they are not working here). Just click on the picture below: